
Applying Fuzzing Techniques Against PDFTron: Part 2
Introduction
In our first blog we covered the basics of how we fuzzed PDFtron using python. The results were quite interesting and yielded multiple vulnerabilities. Even with the number of the vulnerabilities we found, we were not fully satisfied. We eventually decided to take it a touch further by utilizing LibFuzzer against PDFTron.
Throughout this blog post, we will attempt to document our short journey with LibFuzzer, the successes and failures. Buckle up, here we go..
Overview
LibFuzzer is part of the LLVM package. It allows you to integrate the coverage-guided fuzzer logic into your harness. A crucial feature of LibFuzzer is its close integration with Sanitizer Coverage and bug detecting sanitizers, namely: Address Sanitizer (ASAN), Leak Sanitizer, Memory Sanitizer (MSAN), Thread Sanitizer (TSAN) and Undefined Behaviour Sanitizer (UBSAN).
The first step into integrating LibFuzzer in your project is to implement a fuzz target function – which is a function that accepts an array of bytes that will be mutated by LibFuzzer’s function (LLVMFuzzerTestOneInput):
When we integrate a harness with the function provided by LibFuzzer (LLVMFuzzerTestOneInput()), which is Libfuzzer's entry point, we can observe how LibFuzzer works internally.

Recent versions of Clang (starting from 6.0) includes LibFuzzer without having to install any dependencies. To build your harness with the integrated LibFuzzer function, use the -fsanitize=fuzzer flag during the compilation and linking. In some cases, you might want to combine LibFuzzer with AddressSanitizer (ASAN), UndefinedBehaviorSanitizer (UBSAN), or both. You can also build it with MemorySanitizer (MSAN):
In our short research, we used more options to build our harness since we targeted PDFTron, specifically to satisfy dependencies (header files etc..)
To properly benchmark our results, we decided to build the harness on both Linux and Windows.
Libfuzzer on Windows
To compile the harness, first, we need to download the LLMV package which contains the Clang compiler. To acquire a LLVM package, you can download it from the LLVM Snapshot Builds page (Windows).
Building the Harness - Windows:
To get accurate results and make the comparison fair, we targeted the same feature(s) we fuzzed during part1 (ImageExtract), which can be downloaded from here. PDFTron provides multiple implementations of their features in various programming languages, we went with the C++ implementation since our harness was developed in the same language.
When reviewing the source code sample for ImageExtract, we found the PDFDoc constructor, which by default takes the path for the PDF file we want to extract the images from. This constructor works perfectly in our custom fuzzer since our custom fuzzer was a file-based fuzzer. However, LibFuzzer is completely different since it’s an in-memory based fuzzer and it provides mutated test cases in-memory through LLVMFuzzerTestOneInput.
If PDFTron’s implementation of ImageExtract had only the option to extract an image from a PDF file in disk, we can easily workaround this constraint by using a simple trick:
dumping the test cases that LibFuzzer generated into the disk then pass it to the PDFDoc constructor.
Using this technique will reduce the overall performance of the fuzzer. You will always want to avoid using files and I/O operations as they’re the slowest. So, using such workarounds should always be a last resort.
In our search for an alternative solution (since I/O operations are lava!) we inspected the source code of the ImageExtract feature and in one of its headers we found multiple implementations for the PDFDoc constructor. One of the implementations was so perfect for us, we thought it was custom-made for our project.
The constructor accepts a buffer and its size (which will be provided by LibFuzzer). So, now we can use the new constructor in our harness without any performance penalties and minimal changes to our code.
Now all we have to do is change ImageExtract sample source code main function from accepting one argument (file path) to two arguments (buffer and size) then add the entry point function for LibFuzzer.
At this point our harness is primed and ready to be built.
Compiling and Running the Harness - Windows
Before compiling our harness, we need to provide the static library that PDFTron uses. We also need to provide PDFTron’s headers path to Clang so we can compile our harness without any issues. The options are:
-L : Add directory to library search path
-l : Name of the library
-I : Add directory to include search path.
The last option that we need to add is the harness fsanitize=fuzzer to enable fuzzing in our harness.
To run the harness, we need to provide the corpus folder that contains the initial test-cases that we want LibFuzzer to start mutating.
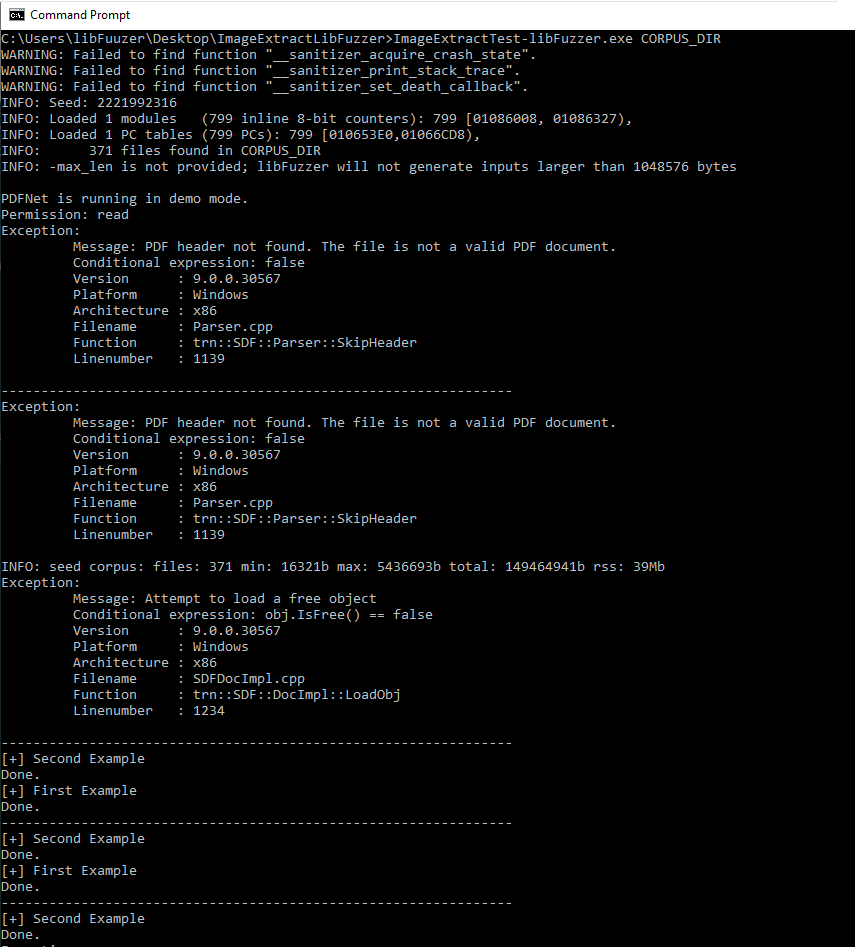
We tested the fsanitize=fuzzer,address (Address Sanitizer) option to see if our fuzzer would yield more crashes, but we realized that address sanitization was not behaving as it should under Windows. We ended up running our harness without the address sanitizer. We managed to trigger the same crashes we previously found using our custom fuzzer (part 1).
LibFuzzer on Linux
Since PDFTron also supports Linux, we decided to test run LibFuzzer on Linux so we can run our harness with the Address Sanitizer option enabled. We also targeted the same feature (ImageExtract) to avoid making any major changes. The only significant changes were the options provided during the build time.
Compiling and Running the Harness - Linux
The options that we used to compile the harness on Linux are pretty much the same as on Windows. We need to provide the headers path and the library PDFTron used:
-L : Add directory to library search path
-l : Name of the library (without .so and lib suffix)
-I : Add directory to the end of the list of include search paths
Now we need to add fuzzer option and the address option as an argument for -fsanitize value to enable fuzzing and the Address Sanitizer:
Our harness is now ready to roll. To keep our harness running, we had to add these two arguments on Linux:
-fork=1
-ignore_crashes=1
The -fork option allows us to spawn a concurrent child and provides it with a small random subset of the corpus.
The -ignore_crashes options allows Libfuzzer to continue running without exiting when a crash occurs.
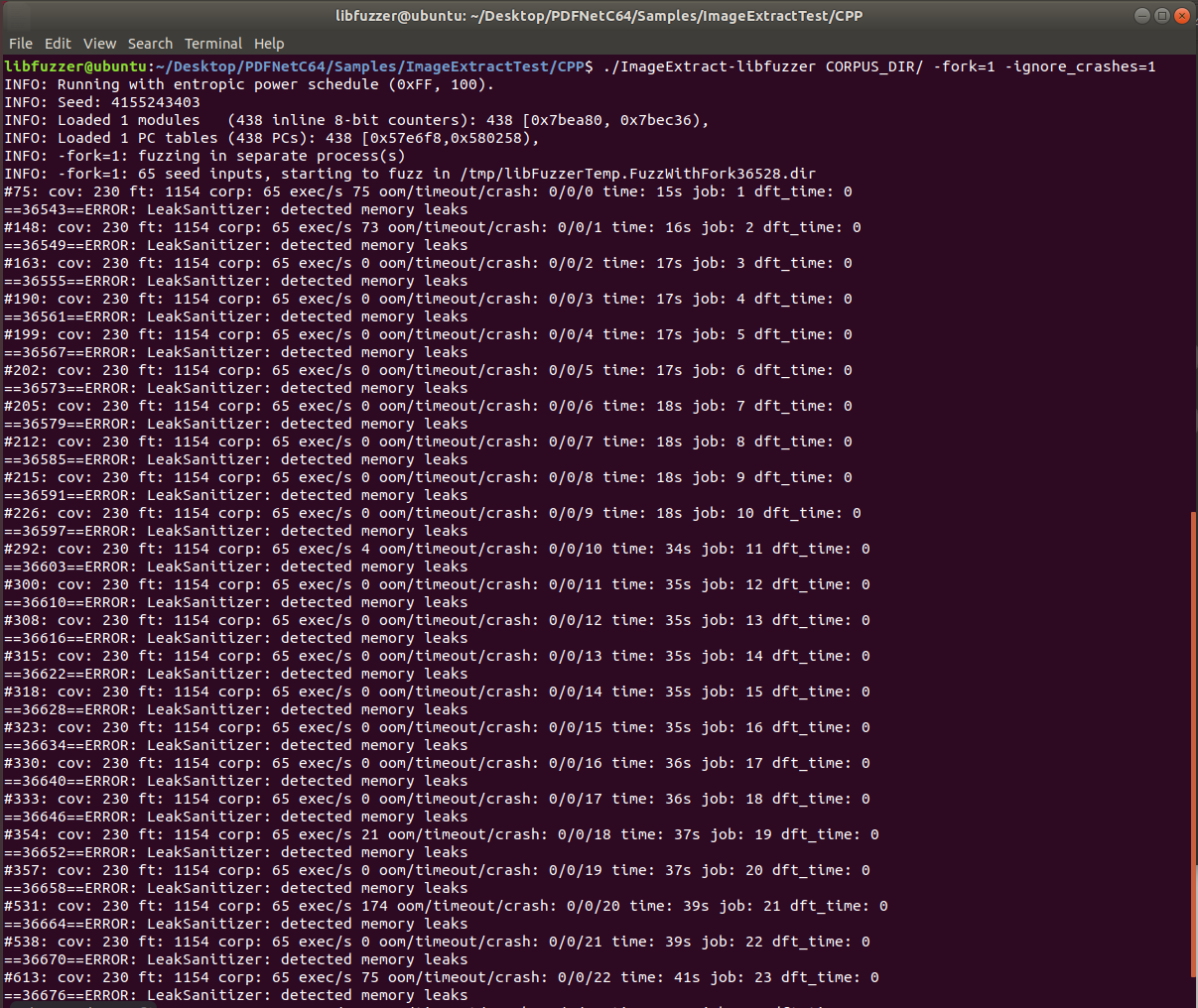
After running our harness over a short period of time, we discovered 10 unique crashes in PDFTron.
Conclusion:
Throughout our small research, we were able to uncover new vulnerabilities along with triggering the old ones we discovered previously.
Sadly, LibFuzzer under Windows does not seem to be fully mature yet to be used against targets like PDFTron. Nevertheless, using LibFuzzer on Linux was easy and stable.
Hope you enjoyed the short journey, until next time!
Happy hunting!