
IDAPython Scripting: Hunting Adobe's Broker Functions
Overview
Recently, many vulnerabilities were fixed by Adobe. Almost all of those vulnerabilities fix issues in the renderer. It’s quite rare to find a bug fixed in Reader’s broker.
Our R&D Director decided to embark on an adventure to understand really what’s going on. What’s behind this beast? is it that tough to escape Adobe’s sandbox?
He spent a couple of weeks reading, reversing and writing various toolset. He spent a good chunk of his time in IDAPro finding broker functions, marking them, renaming them and analyzing their parameters.
Back then I finished working on another project and innocently asked if he needs any help. Until this day, I’m still questioning myself whether or not I should have even asked ;). He turned and said: “Sure I think it would be nice to have an IDAPython script that automatically finds all those damn broker functions”. IDAPython, what’s that? Coffee?
First, IDA Pro is one of the most commonly used reverse engineering tools. It exposes an API that allows automating reversing tasks inside the application. As the name implies, IDAPython is used to automate reverse engineering tasks in python.
I did eventually agree to take on this challenge - of course without knowing what I was getting myself into.
Throughout this blog post, I will talk about my IDAPython journey. Especially with the task that I signed myself to, writing an IDAPython script that automatically finds and flags broker functions in Acrord32.exe
Adobe Acrobat Sandbox 101
When Acrobat Reader is launched, two processes are usually created. A Broker process and a sandboxed child process. The child process is spawned with low integrity. The Broker process and the sandboxed process communicate over IPC (Inter-Process Communication). The whole sandbox is based on Chromium’s legacy IPC Sandbox.

The broker exposes certain functions that the sandboxed process can execute. Each function is called a tag and has a bunch of parameters. The whole architecture is well documented and can be found in the references below.
Now the question is, how can we find those broker functions? How can we enumerate the parameters? Here comes the role of IDAPython.
Now let's get our hands dirty...
Scripting in IDAPython
After some research and reversing, I deduced that all the information we need is contained within the '.rdata' section. Each function with its tag and parameters have a fixed pattern which is 52 bytes followed by a function offset, and looks as follows:

Some bytes were bundled and defined as ‘'xmmword'’ instructions due to IDA’s analysis.
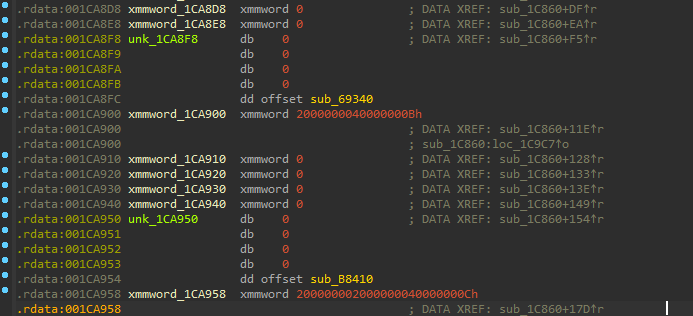
In order to fix this, we undefine those instructions by right-clicking each one and selecting the undefine option in ida. Ummm... but what if there are hundreds of them? Wouldn't that take hours? Yup, that’s definitely not efficient. Solution? You guessed it, IDAPython!
The next thing we need to do is convert all those bytes (db) to dwords (dd) and then create an array to group them together so we can get something that looks like the following:

At 0x001DE880 we have the function tag which is 41h. At 0x001DE884 we have the three parameters 2 dup(1) (two parameters of type 1) and a third parameter of type 2. Finally, at 0x001DE8D4 we have the offset of the function.
Since now we know what to look for and how to do it, let’s write a pseudo-process to accomplish this task for all the broker functions:
1. Scan the '.rdata' section and undefine all unnecessary instructions (xmmword)
2. Start scanning the pattern of the tag, parameters, and offset
3. Convert the bytes to dwords
4. Convert the dwords to an array
5. Find all the functions going forward
5. Display the results
The Implementation
First, we start off by writing a function that undefines xmmword instructions:
As all our work will be in '.rdata' section, we utilize the 'get_segm_by_name' function from the Idaapi package, which returns the address of any segment you pass as a parameter. Using the startEA and endEA properties of the function, we determined the start and the end addresses of the '.rdata' section.
We scan the '.rdata' section using GetDisasm() function to check for any xmmword we stumble across. Once we do encounter an xmmword then we apply the do_unknown() function which undefines them.
The itemSize() function is used to move and proceed with one instruction at a time.
Next, we check if there are 52 bytes followed by a function offset containing the string 'sub', then pass the starting address of that pattern to the next function, convertDword().
This convertDword function takes the start address of the pattern and converts each 4 bytes to dwords then creates an array out of those dwords.
Having executed the previous function on the entire '.rdata' section, we end up with something similar to the following:

Next, we grab the functions and write them into a file and put them into a new window in IDAPro.
As for the argument types? Sure, here’s what each match to:
The next step is to scan the data section and convert all arguments type numbers to the actual type name to be displayed later.
As I mentioned before, there’s a tag of type dword followed by the parameters which always includes dup() and then followed by a function offset that always contains 'sub' string. We split the parameters and pass the list returned to remove_chars() function which removes unnecessary characters and spaces, lastly we pass the list to remove_dups() function to remove the dup() keyword and replace it with the number of parameters (will be explained in a bit).
Before explaining this function, lets explain what does dup(#) means, if we have for example “2 dup(3)” this means we have 2 parameters of type 3, if we have a number with dup(0) that means we can remove that parameter because it’s an invalid type as we saw earlier in the table we have.
That said, this function is straight forward, we iterate over the list containing all the parameters. We then remove all spaces and characters like 'dd' from the instruction. If there is a dup(0) in the list we just pop that item from the list, and return an array with only valid parameters. so now the next step is to replace dup() with how many numbers in front of it. For example if we have 5 dup (2) that would result 2, 2, 2, 2, 2 in the array.
We iterate over the list using regex to extract the number between dup() parenthesis and append the number extracted based on the number before the dup() just like the example we discussed earlier. After this, we will have a list of numbers only which we can iterate over and replace each parameter type number to its corresponded type.
Finally, the results are written to a file. The results are also written to a new subview in IDA.

Conclusion
It was quite a ride. Maybe I should have known what I was getting myself into. Regardless, the end result was great. It’s worth noting that I ended up sending the directory many output iterations with wrong results – but hey, I was able to get it right in the end!
Finally, you’d never understand the power of IDAPython until you actually write IDAPython scripts. It definitely makes life much easier when it comes to automating RE tasks in IDAPro.
Until next time..
References